Whether you’re searching for a new restaurant, scrolling through your social media or just getting laughs watching cat videos you have ads to thank for sponsoring this experience. When ads are good, you don’t notice them , when they are bad you get irritated and when they are unbelievably good you get creeped out.
- An Overview
- Ads Mixer
- Ads Index
- Retrieval
- Ranking
- Auction
- The Challenges
- Lots of ML problems
- Further Reading
In this post, we will look at how these ad systems are built. To be sure, these systems are behemoths and there are entire office blocks at your friendly neighborhood social media companies where folks work hard to get users to click a little more. Our goal is to understand what the major components are and how they fit together. We will skip over some details but hope to cover the important bits in some depth.
A lot of what goes into making ads relevant and personalized is useful for all sorts of recommenders. And if you squint hard enough, most problems can start looking like recommendation problems.
In this first post let’s take a bird’s eye view of the whole enchilada and try to scope out what the shape of the problem is.
An Overview
When you type in a search query like “used cars” in google, the top search results are all ads for car dealerships. Scroll a bit lower and you start seeing the non-promoted or organic results. Each time you click on one of the ads, google (the platform) makes a tiny bit of money. The car dealerships (the advertisers) all bid for the “used cars” search query and when someone actually clicks on an ad, google gets paid by that advertiser.
On twitter or facebook like homepage feeds, the “query” is You, the user. Ads are personalized based on the trail of interaction data (watches, clicks, likes) that users leave behind. For youtube or Instagram like apps the query could mean a video or image.
Now these platforms of course want to get paid a lot. So they try real hard to show you the ads that you are most likely to click. Within a ~100 milliseconds, a lot of ML models whir silently to show you the handful of relevant ads, selected from a humongous corpus that could have hundreds of millions of ads.
Take a minute to look at the picture below.
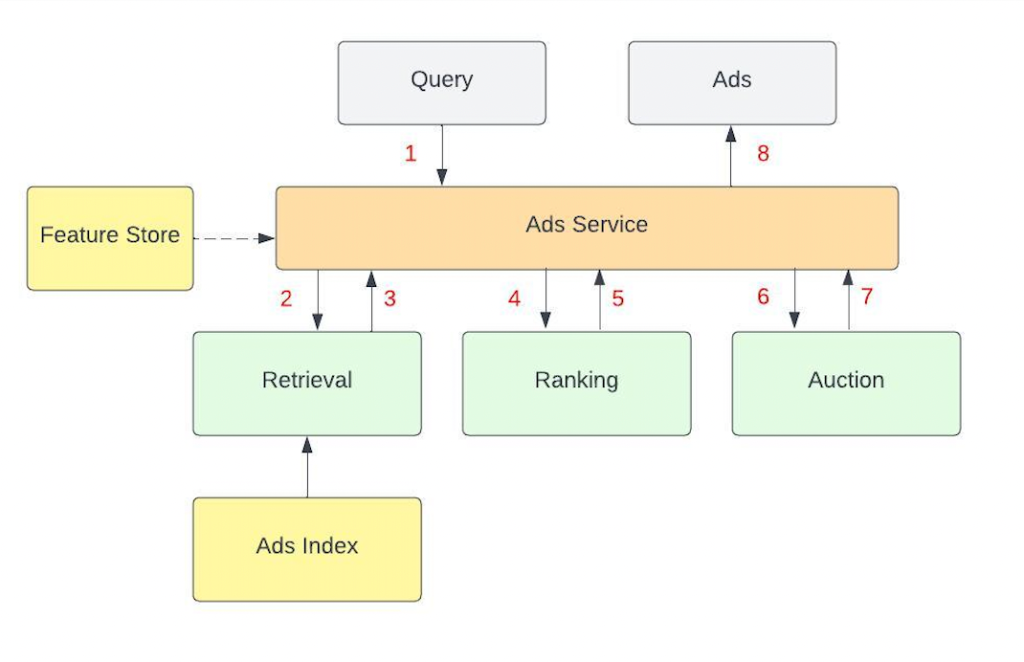
The numbers next to the arrows indicate how things are usually sequenced. The Query (number 1) starts off the whole flow which ends when Ads are shown. (number 8). The Query here includes the user and whatever context is available. The context could include a search phrase, a video or an image for example. Not shown here is how the ads and organic results are finally put together to render the entire page.
Retrieval , Ranking and Auction is where most of the action is. A good way to visualize this is to imagine how ads flow through this funnel. At each step, the number of candidates drop by an order of magnitude. This separation between the funnel components is what allows the platform to serve up relevant ads quickly.
The feature store (in figure 1) which stores all the features required by the ML model has dotted arrows going back and forth because these requests could happen in parallel with other stuff.
Let’s take a look at each of these high level components.
Ads Mixer
The Ads Mixer is the interface through which requests flow. It coordinates all the calls to various services and finally puts together the ranked list of ads that get shown to the user. The Mixer is also usually responsible for fetching the features used by ML models from the Feature Store. For example after retrieval we might have a thousand ad candidates, each of which will be run through many Ranking ML models (in parallel) . Doing this feature hydration once in the Ads Mixer saves each of the rankers having to do it separately.
Ads Index
This is the “database” where all ads are stored. Ads are created when advertisers set up campaigns. For example, a car dealership could set up an ad with some nice looking pictures and text (called the creative) and specify how much money (called the budget) they are willing to spend. They also usually specify targeting criteria like geography and user demographics. Batch and streaming updates keep the Ads Index fresh and accurate.
Retrieval
This is where we cast a wide net over the Ads Index and quickly find the best ~ 1000 ad candidates for the query. Speed is of essence here and the ML models used are optimized for low latency. Plenty of non ML approaches also do grunt work here. Some typical approaches in this layer could include
- Rules like geo and demographic targeting. Some ads are targeted very broadly.
- Traditional text based systems like Lucene where documents are the ads and the query is constructed from the user’s data and other context.
- Approximate similarity searches in an embedding space. The heavy work of learning embeddings for the ads is done offline and only the query has to be transformed into an embedding at run time. Two tower DNN’s are a popular approach to learn good embeddings. Libraries like HNSWlib and Annoy have made approximate similarity searches very fast.
- Random walks on a Graph. In some applications, the graph is obvious (friend graphs on Facebook), but in many other applications, with a bit of creativity it’s possible to model user interactions as a graph. Once the graph is built, walking it can generate a very good set of candidates very fast.
- Matrix Factorization on User and Ad interaction data. Two Tower DNN’s have replaced these techniques.
We will talk about Retrieval in more depth in a follow-up post.
Ranking
This is where the list of potential candidates selected by Retrieval are scored by large ML models . Most of the time in the entire Ads Serving system is usually spent here. Since we are only ranking a few thousand candidates, we are free to use large ML models optimized for accuracy. There are usually quite a few Ranking models and they can all be parallelized. Here is a small sample of the ranking models typically used.
- The most important prediction is the probability of the ad being clicked. For ads, this also needs to be well calibrated. For other recommenders, just ranking by some score might be good enough, but for ads we want the predicted click probability to be very close to observed click probability, since revenue estimates are based off this.
- Ranking only by probability of click can give very click-baity ads. To counter this , there are models that predict the probability of a long click . The intuition is that users will quickly bounce out of a click-baity ad but they will spend more time on a “good” ad.
- We might also want to have a notion of relevance that is not based on clicks. For example models trained on explicit feedback about the relevance of an ad either from users or specially dedicated folks
- Sometimes we care about user actions beyond clicks. For example if the ad is for a product, we might care if the product is actually purchased and need models that can predict purchase.
All these model scores are combined in some way in the final ranking utility function, which is the “secret sauce” unique to each platform. Secret sauce is usually a euphemism for fine tuned (over years) heuristics and techniques that are not based on gradient descent if you catch the drift !
Models used in this stage also need to be refreshed in near real time. We will look at Ranking in much more depth in a follow up post.
Auction
This is where the money is made. Every Ad candidate that enters the auction has a bid, which is what the advertiser is willing to pay the platform if the ad gets clicked. The auction ranks the ads by “expected revenue” . This is how much the platform can expect to be paid. Multiplying the bid by the probability of the click gives us this “expected revenue”. There is a lot of economic theory that goes into designing efficient auctions and we will talk a bit more about auctions in a follow up post.
Now finally, after the auction the ads that “won” the auction are displayed to the user.If the ads are any good, the user will click on a few and everyone is happy !
The Challenges
An Ads platform has to balance the (sometimes competing) needs of the Users, Advertisers and itself. Let’s try and understand the tradeoffs .
The biggest question for the platform is how to balance the short term with the long term. The platform can always make more money by showing more ads and less organic content, but ads are generally not as good as the organic content.
Notice how ads are not only ranked by probability of getting clicked. Bid enters the auction and the end result for the user is that advertisers can pay their way to get ahead of more relevant content. Of Course if the platform gets greedy and shows too many ads of questionable relevance, users get pissed off and go elsewhere. How do platforms deal with this ?
Well, the good ones hope for the magical flywheel effect. The thinking is that showing good stuff to the users, should bring in more users. Advertisers follow the users and now there is a bigger pool of advertisers who are willing to bid higher in the auction. This gives the platform more leverage in showing only good ads. For example the platform could simply filter out ads after the ranking models if their predicted “goodness” is too low.
Lots of ML problems
These are some other questions that affect the entire Ads serving funnel. Most of these are ubiquitous to any large scale ML problem.
- The data changes very rapidly. We need to train models on a very large amount of data and most models (especially in the Ranking stage) benefit from near real time updates.
- Offline ML metrics don’t always mirror online metrics. Implicit labels (like clicks) are inherently noisy. Our ML model metrics like AUC or precision are proxies for what the users really care about and optimizing for these does not always directly lead to real progress.
- Changing one thing changes everything. Ads flow through retrieval, ranking and auction. A small change in Retrieval might change the kind of ads that go into ranking. Suddenly the ranking ML models are seeing a “new” distribution and a whole chain reaction of side effects can start. Managing these kinds of dependencies is a challenge and requires work.
- The training & serving distribution is almost never the same. Theoretical purists get worked up when they see one of the foundational commandments of ML get violated. Most of the training data for the ML models comes from what the users see and interact with. During serving the models, actually see a distribution that is before this in the funnel
- Cold start is usually a bigger deal for ads. The best organic content for a query is likely to stay alive for a long time, but ads tend to be created and die (or run out of advertiser budgets) much faster. Ads also usually have a much lower click through rate (< 1%) . User’s (sadly for the platform) interact with Ads much lesser than what Advertisers hope for.
Hopefully this overview has been useful and sets the stage for digging deeper in subsequent posts. I plan to at least talk about a few approaches in Retrieval and Ranking, focussing on the Machine Learning bits .
Thank you for reading and if you have any questions please leave a comment below.
Further Reading
- Great write up from Twitter about their ads architecture
- How snap does ad ranking
- Facebook explaining how it’s ads work. This post is meant for the general FB user.

Leave a comment